Cluster Reference
更新时间:2021-10-19
根据《官方手册》 撰写本文 有任何问题请告诉我。烦请阅读完全文再进行测试,感谢!
1. 登录/登出
所有用户从管理节点登录,IP地址为 10.xx.xx.xx
在Windows 10下,可以直接在命令行中输入
ssh 用户名@10.xx.xx.xx
登录到管理节点。也可参考官方手册使用其它客户端(如putty , MobaXterm)登录。登录端口号为默认的22,不是23。
初始密码为,第一次登录后建议立即输入命令
$ passwd
修改密码,并牢记!
使用命令exit或logout登出账户。
2. 上传/下载/打包文件
使用winscp 软件。可参考官方手册,登录端口号为默认的22,不是23。
文件保存在自己的home目录下
/gpfsdata/home/用户名
如需传输大量文件,务必先打包。可以使用pigz工具缩短压缩时间(先执行4.8 其他从源码编译的工具)。在需要压缩的目录的上一级执行
$ tar --use-compress-program=pigz -cf 压缩包名.tar.gz ./需要压缩的目录
3. 使用LSF系统提交任务
平台通过LSF软件统一调度所有的任务和计算资源,用户则通过bsub提交任务。
也就是说,执行程序的方法是
在管理节点(也就是登录节点)上,把运行参数和命令写成一个脚本,提交给LSF,LSF将任务分配到计算节点上运行。
脚本通常需要三个部分:
- 请求多少CPU、GPU等资源的参数,本节讲述的内容
- 环境变量
- 运行命令
4节提供了脚本的完整的示例。
注意 不要直接ssh到计算节点上执行程序!(可以短时间调试代码)
ssh上运行的程序在登出或掉线后会被退出,bsub提交的不会。
官方手册的第6、7部分提供了集群LSF平台的操作方法,但存在一些错误。不同之处请优先参考下文:
3.1 bsub参数
可以在脚本中设置参数来控制LSF如何为我们分配计算资源。
CPU资源
#BSUB -n 16
#BSUB -R "span[ptile=16]"
这两行的含义分别是总共使用16个CPU核心和单个节点上使用16个核心。将程序放在多个节点上运行通常会降低性能,因此-n和ptile通常相等,表示只在一个节点上运行。
如果要在多个节点上运行(很少用到),比如
#BSUB -n 48
#BSUB -R "span[ptile=24]"
#BSUB -m "nodeXX nodeXX"
第三行表示指定在哪几个节点上运行(可以省略)。
关于具体使用的CPU核心数量,可以设置为4或6的倍数。但分配的核心数量越多,并行效率越低,尤其对于科学运算,过多的核心数反而会延长运行时间!建议在CPU节点上设为24或32但不超过48,在GPU节点上设为8或12但不超过24。
注意 这里设置的核心数仅表示分配给程序的资源,在程序在执行时还需另外指定使用多少核心(见4节)。
GPU资源
#BSUB -q gpuq
#BSUB -R "rusage[ngpus_shared=2]"
这两行的含义分别是将任务提交到GPU节点队列(默认是CPU节点队列),使用2个GPU核心。
3.2 提交脚本
在home目录下新建一个lsf文件夹,进入lsf文件夹并将脚本保存在此文件夹内,执行
$ bsub < 脚本名
当任务运行结束或用bkill结束任务后,将产生error和output文件。使用less可以查看这些文件。
3.3 其它LSF命令
官方手册的第6、7部分提供了集群LSF平台的基本操作方法,包括监控作业情况、手动终止作业、查看集群中所有的队列信息、查看所有节点的资源信息等。
更详细的资料请参考压缩包中随附的
- 2[参考]LSF作业调度系统的使用中科大.pdf
- 3[参考]Running Jobs with Platform LSF.pdf
4 软件使用范例
所有的软件都已经安装在
/gpfsdata/apps/sharedZJULI/
这个公共路径下,在设置好相应的环境变量后就能够使用了。
需要共享的文件可以放在/gpfsdata/apps/sharedZJULI/public下,除此以外,
不要修改、添加、删除 sharedZJULI 这个路径下的任何文件!
环境变量每次登录都要重新设置(实际通过脚本设置,无需手动设置,详见各部分相应的完整LSF脚本示范)。
4.1 TensorFlow PyTorch
建议自行安装Anaconda来安装这些Python包。可参考这里。
以下为在集群上运行的参考方式。
环境变量
安装完成后,使用前需执行两步:
$ eval "$(/gpfsdata/apps/sharedZJULI/opt/miniconda3/bin/conda shell.bash hook)"
$ conda activate conda环境名
TensorFlow的conda环境名是tf, PyTorch的conda环境名是torch。
也可自行安装conda使用。
使用GPU的程序需在GPU节点上运行,详见3.1 bsub参数
如需安装其他包请告知我。
完整LSF脚本示范 (tensorflow gpu, acquire 8 cores and gpu)
#!/bin/bash
#BSUB -J jobname
#BSUB -q gpuq
#BSUB -n 8
#BSUB -R "span[ptile=8] rusage[ngpus_shared=2]"
#BSUB -o output_%J
#BSUB -e errput_%J
cd /gpfsdata/home/your_user_name/my_python_script_folder
eval "$(/gpfsdata/apps/sharedZJULI/opt/miniconda3/bin/conda shell.bash hook)"
conda activate tf
python my_tensorflow_code.py
4.2 MATLAB
环境变量
MATLAB 2017b已安装在/gpfsdata/apps/sharedZJULI/opt/MATLAB2017b/。
在mgt和fat01节点上,运行以下命令可直接启动MATLAB
$ /gpfsdata/apps/sharedZJULI/opt/MATLAB2017b/bin/matlab -nodesktop
但在其它节点上,运行MATLAB前还需先配置环境变量
$ export LD_LIBRARY_PATH=/gpfsdata/apps/sharedZJULI/LD/matlab:$LD_LIBRARY_PATH
再执行上一步。
完整LSF脚本示范 (acquire 2 cores)
#!/bin/bash
#BSUB -J matlab
#BSUB -n 2
#BSUB -R "span[ptile=2]"
#BSUB -o output_%J
#BSUB -e errput_%J
export LD_LIBRARY_PATH=/gpfsdata/apps/sharedZJULI/LD/matlab:$LD_LIBRARY_PATH
cd MATLAB_code_folder
/gpfsdata/apps/sharedZJULI/opt/MATLAB2017b/bin/matlab -nodisplay -sd MATLAB_code_folder -r "run('script_file.m');exit;"
-nodisplay表示禁用图形界面,-sd为MATLAB的工作目录,-r为运行MATLAB的命令,其中run函数的参数为脚本文件名称,output文件中记录了MATLAB运行过程中的文本输出。
MATLAB运行完成后的所有结果(如图片、数据)均需手动添加代码将其保存为文件。
MATLAB的并行效率取决于代码本身。除非明确代码是并行编程或使用并行优化的软件包,不建议请求过多的cores!
4.3 FEKO
环境变量
FEKO 2017已安装在
/gpfsdata/apps/sharedZJULI/opt/feko2017
需要先设置依赖库环境变量
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/gpfsdata/apps/sharedZJULI/LD/kefo
上传.fek文件后即可运行仿真。
完整LSF脚本示范 (Single Host, acquire 12 cores)
#!/bin/bash
#BSUB -J jobname_like_feko
#BSUB -n 12
#BSUB -R "span[ptile=12]"
#BSUB -o output_%J
#BSUB -e errput_%J
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/gpfsdata/apps/sharedZJULI/LD/feko
cd ~/feko
/gpfsdata/apps/sharedZJULI/opt/feko2017/altair/feko/bin/runfeko your_feko_file_name --use-job-scheduler
其中your_feko_file_name为fek文件的文件名(不含后缀)。--use-job-scheduler读取上文中的计算资源配置,不可省略。
请注意在脚本中出现的 两次 “12”,须保持一致!
4.4 COMSOL
COMSOL 5.5已安装在
/gpfsdata/apps/sharedZJULI/opt/comsol55/multiphysics
需要事先在自己电脑上将仿真文件设置为批处理模式:
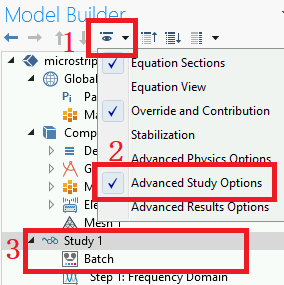
- 在 “模型开发器”树中,单击显示按钮并选择高级研究选项
- 在 “模型开发器”中,右键单击研究节点并选择批处理,以创建批处理作业
- 要运行特定的研究,可以添加命令行选项 -study tag,其中 tag 是待运行研究的标记,例如 std1 (若为中文,请修改为英文,若含空格(默认为Study 1,含空格),请删除)
如果仿真文件中已有运行结果,请先删除以减小文件体积!
完整LSF脚本示范 (Single Host, acquire 12 cores)
#!/bin/bash
#BSUB -J jobname
#BSUB -n 12
#BSUB -R "span[ptile=12]"
#BSUB -o output_%J
#BSUB -e errput_%J
cd /gpfsdata/home/user_name/lsf
/gpfsdata/apps/sharedZJULI/opt/comsol55/multiphysics/bin/glnxa64/comsol \
batch -inputfile ~/comsol/microstrip_patch_antenna_inset.mph \
-outputfile ~/comsol/out.mph -np 12
请注意在脚本中出现的 三次 “12”,须保持一致!
仿真完成后,可配合5.1节运行
/gpfsdata/apps/sharedZJULI/opt/comsol55/multiphysics/bin/glnxa64/comsol
直接查看图形结果。
4.5 HFSS
环境变量
Ansys Electroonics 2020R1已安装在
/gpfsdata/apps/sharedZJULI/opt/AnsysEM/AnsysEM20.1/Linux64
需要先设置依赖库环境变量
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/gpfsdata/apps/sharedZJULI/LD/hfss
完整LSF脚本示范 (Single Host, acquire 4 cores)
#!/bin/bash
#BSUB -J jobname
#BSUB -n 4
#BSUB -R "span[ptile=4]"
#BSUB -o output_%J
#BSUB -e errput_%J
cd /gpfsdata/home/your_user_name/lsf
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/gpfsdata/apps/sharedZJULI/LD/hfss
/gpfsdata/apps/sharedZJULI/opt/AnsysEM/AnsysEM20.1/Linux64/ansysedt \
-Ng -Machinelist list="localhost:1:4:90%:0" \
-Batchsolve ~/your_hfss_file.aedt
在最后一条运行命令中,-Ng表示禁用图形界面,list后的参数分别表示<machine name>:<tasks on machine>:<cores on machine>:<RAM%>:<nums of gpu>。
HFSS的并行效率较低,不建议请求过高的cores!
请注意在脚本中出现的 三次 “4”,须保持一致!
仿真完成后,可配合5.1节运行
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/gpfsdata/apps/sharedZJULI/LD/hfss
/gpfsdata/apps/sharedZJULI/opt/AnsysEM/AnsysEM20.1/Linux64/ansysedt
直接查看图形结果。
4.6 Lumerical FDTD
环境变量
Lumerical 2016b已安装在
/gpfsdata/apps/sharedZJULI/opt/lumerical/fdtd
需要先设置依赖库环境变量
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/gpfsdata/apps/sharedZJULI/LD/lumerical
完整LSF脚本示范 (Single Host, acquire 24 cores)
#!/bin/bash
#BSUB -J jobname
#BSUB -n 24
#BSUB -R "span[ptile=24]"
#BSUB -o output
#BSUB -e errput
cd /gpfsdata/home/user_name/lsf
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/gpfsdata/apps/sharedZJULI/LD/lumerical
/gpfsdata/apps/sharedZJULI/opt/lumerical/fdtd/mpich2/nemesis/bin/mpiexec -n 24 \
/gpfsdata/apps/sharedZJULI/opt/lumerical/fdtd/bin/fdtd-engine-mpich2nem -t 1 \
~/lumerical_file.fsp
请注意在脚本中出现的 三次 “24”,须保持一致!
Lumerical软件并行效率最高在24左右,不建议请求过高的cores!
仿真完成后,可配合5.1节运行
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/gpfsdata/apps/sharedZJULI/LD/lumerical
/gpfsdata/apps/sharedZJULI/opt/lumerical/fdtd/bin/fdtd-solutions
直接查看图形结果。
完整LSF脚本示范2 (Multi Host, NOT recommend, acquire 2 nodes and 24 cores in each node(11,13))
#!/bin/bash
#BSUB -J jobname
#BSUB -n 48
#BSUB -R "span[ptile=24]"
#BSUB -m "node11 node13"
#BSUB -o output_%J
#BSUB -e errput_%J
cd /gpfsdata/home/user_name/lsf
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/gpfsdata/apps/sharedZJULI/LD/lumerical
/gpfsdata/apps/sharedZJULI/opt/lumerical/fdtd/mpich2/nemesis/bin/mpiexec \
-hosts node11:24,node13:24 \
/gpfsdata/apps/sharedZJULI/opt/lumerical/fdtd/bin/fdtd-engine-mpich2nem -t 1 \
~/lumerical_file.fsp
4.7 CST
还在调试中
4.8 其他从源码编译的工具
包含一些从源码编译的工具(最新版)
- Python 3.7
- Screen 4.6.2
- Pigz (并行压缩)
执行
$ export PATH=$PATH:/gpfsdata/apps/sharedZJULI/bin
之后即可使用。
如需安装其他工具请告知我。
5. 其他事项
5.1 使用图形界面
Linux使用图形界面会占用大量带宽,即使是100M带宽也会占满并严重卡顿,大量用户使用时会造成网络拥堵。
建议仅在仿真完成后查看结果时使用图形界面。
建议先远程到Windows账户上,通过十万兆网卡(IP为172.16.1.254)ssh到管理节点 上使用图形界面,降低网络负载。
方法1
安装xming并启动;
运行putty,在左侧依次找到Connection-SSH-X11,将Enable X11 forwarding打勾。
方法2
使用MobaXterm,默认已启用X11转发。点击软件左上角的Session,选择SSH,输入IP即可连接。